112
ЭКСПЕРИМЕНТАЛЬНЫЕ МЕТОДИКИ И АППАРАТУРА
МЕТОДИКА ОПРЕДЕЛЕНИЯ СТРУКТУРЫ МАЛОЙ ГРУППЫ
С ПОМОЩЬЮ ФОРМАЛИЗОВАННОГО АНАЛИЗА
МЕЖЛИЧНОСТНЫХ ВЫБОРОВ
А.С. ГОРБАТЕНКО, Т.М. ГОРБАТЕНКО
Выделение подгрупп как структурных единиц группы является необходимым для адекватного понимания интрагрупповой активности. Строго говоря, при анализе структуры межличностных отношений следует рассматривать группу не только как систему индивидуальных межличностных отношений, но и как систему отдельных подгрупп (если такое деление реально присуще группе), и определять любой интересующий исследователя параметр не только для группы в целом, но и для каждой подгруппы в отдельности.
Я.Л. Коломинский считает, что «уже сейчас в возрастной педагогической социальной психологии разработаны надежные методы диагностики микрогрупповой дифференциации малых групп и коллективов» [3; 66]. Действительно, многие авторы, использовавшие социометрическую методику для исследования структуры группы, сталкивались с фактом наличия в группах относительно замкнутых сплоченных, «самодостаточных» подгрупп. Однако изучение подгрупп как специальное направление исследования структуры группы не получило должного развития в социальной психологии, несмотря на то что многие авторы справедливо считают это направление перспективным и практически важным. Основной причиной этого, на наш взгляд, является отсутствие достаточно формализованного и вместе с тем простого метода определения- количества и состава подгрупп в группе.
Исследователи, предпринимавшие попытки создания формализованного метода выделения подгрупп, неизбежно сталкивались с решением двух основных вопросов: 1) по каким критериям определяется принадлежность данного индивида к подгруппе?; 2) с помощью какого алгоритма можно выделить подгруппы, если заранее не известны ни их количество в группе, ни их состав?
Принадлежность индивида к подгруппе можно определить на основании самых разнообразных критериев: непсихологических, таких, как рост, вес, возраст, профессия, квалификация, успешность деятельности, зарплата и т.д. и психологических, таких как сходство установок, ценностей, личностных характеристик, мнение лидера, руководителя, эксперта и т.д. Однако при разделении группы на подгруппы по этим критериям, как правило, не требуется использование специальных математических процедур. Такое разделение обычно достаточно очевидно.
Принадлежность индивида к подгруппе можно определить и на основе его включения в определенную n-цепь, в которой индивиды связаны не только прямо, но и опосредованно. Однако ни в коем случае не отрицая возможности опосредованной связи индивидов в группе, необходимо отметить, что рассмотрение n-цепей в целях выделения подгрупп является эвристически малоценным. Действительно, последовательное, строгое и формализованное применение этого подхода привело бы к тому, что в одну подгруппу нужно было бы объединить всю группу, члены которой связаны друг с другом с различной степенью опосредованности. Компромиссные варианты, предусматривающие совмещение нескольких подходов к определению принадлежности индивида к подгруппе (например, одновременно на основании мнения лидера группы и включенности в n-цепь), с одной стороны, не имеют достаточных теоретических оснований и не представляют большого практического интереса, с другой, приводят к очень серьезным, но совершенно неоправданным техническим трудностям.
Иное дело, когда принадлежность человека к подгруппе определяется на основании анализа межличностных выборов, отражающих отношения, складывающиеся между членами группы. Такое разделение на подгруппы является фактической структурной характеристикой группы, представляющей для исследователей как теоретический, так и практический интерес. В то же время такое разделение ее очевидно, но может быть раскрыто после применения специального математического аппарата.
При этом возможны три различных варианта определения принадлежности человека к подгруппе: 1) на основании его собственного мнения (или производимых им выборов), 2) на основании мнения членов подгруппы (их выборов), 3) в результате совпадения собственного мнения человека и мнений членов подгруппы (взаимных выборов).
Именно на последнем варианте останавливается большинство исследователей. Однако строгое, формализованное применение этого варианта предполагает, что все без исключения члены подгруппы должны быть связаны друг с другом взаимными выборами. В реальной жизни взаимность выборов членов подгруппы нарушается, члены подгруппы связаны между собой не только непосредственно, но и опосредованно, не прямо. В этом случае необходимо было бы либо сокращать число рассматриваемых членов подгруппы
113
(что не соответствовало бы реальности), либо возвращаться к применению одного из первых двух вариантов оценки принадлежности человека к подгруппе.
При рассмотрении этих двух вариантов предпочтение, очевидно, должно быть отдано мнению членов подгруппы. Этот вариант в большей степени соответствует психологической традиции, предполагающей важную детерминирующую роль группы по отношению к личности. В практических социометрических исследованиях именно на основании обобщенного мнения членов группы судят об «отверженности» члена группы или его принадлежности группе и включенности в систему внутригрупповых межличностных отношений. Кроме того, использование мнения всех (или большинства) членов подгруппы, а не одного человека, позволяет существенно повысить статистическую достоверность принадлежности человека к подгруппе. Отметим также, что в подгруппе, сформированной по этому принципу, будет максимальное количество взаимных выборов.
Однако исследователи практически не пользовались этим вариантом определения принадлежности человека к подгруппе, поскольку возникает кажущийся порочный логический круг: для того чтобы определить лиц, составляющих подгруппу, надо узнать их мнение.
Выход из этого логического круга возможен при решении второго основного вопроса, связанного с созданием формализованного алгоритма выделения подгрупп. Проанализированные В.И. Паниотто алгоритмы выделения подгрупп [5; 69—73] недостаточно формализованы и дают результаты, зависящие от случайных факторов, например от выбора начальных точек классификации. В принципе, для решения задач подобного типа наиболее подходящими являются математические методы распознавания образов, которые позволяют группировать переменные, не задавая заранее ни число подгрупп (кластеров, таксонов), ни их состав. Известны алгоритмы численной таксономии «без учителя», успешно применяющиеся и дающие устойчивые результаты при группировке других социальных объектов, например пунктов опросников [1]. Однако данный алгоритм, в силу специфичности задачи, не может быть прямо использован для выделения подгрупп в группах.
В связи с этим нами был разработан метод численной таксономии «без учителя» специально для выделения подгрупп в группе. Общие принципы таксономии просты и сводятся к следующему: 1) составляется «матрица описания», которая характеризует конкретное состояние группируемых переменных; 2) по определенным критериям устанавливаются численные значения связей (сходства) между всеми группируемыми переменными и строится «матрица коэффициентов сходства»; 3) по определенному формализованному принципу производится группировка переменных в таксоны (кластеры, подгруппы) и определяется коэффициент, характеризующий качество данной группировки; 4) в том случае, если группировка производилась неоптимальным образом или качество группировки ее удовлетворяет определенным критериям, может производиться перегруппировка переменных.
Рассмотрим, как были реализованы эти принципы в конкретном алгоритме:
1. В случае, когда перед исследователем возникает задача выделения подгрупп, в качестве матрицы описания может выступать обычная социометрическая матрица. При этом необходимо помнить, что выделенные подгруппы будут однородны по заданному социометрическому критерию. Поэтому если в качестве такого критерия использовать «сильные» конкретные критерии предпочтительности («С кем хотел бы...»), то образовавшиеся подгруппы будут отражать один из частных случаев желаемой для индивидов, а не реальной структуры группы. В связи с этим для выделения подгрупп предпочтительнее использовать такие критерии, которые традиционно считаются «слабыми» [4; 95], неконкретными и направленными на определение не предпочтений, а реальной сферы общения и взаимодействия человека. (Например: «Выберите из числа членов группы тех людей, с которыми вы общаетесь чаще всего, поддерживаете наиболее тесные отношения».) Не следует ограничивать возможное число выборов испытуемых. В противном случае эти общие, одинаковые для всех членов группы ограничения могут сказаться на численности выделенных подгрупп. Для дальнейшей обработки каждый выбор испытуемых кодируется как «1» и заносится в обычную социометрическую матрицу. На главную диагональ социометрической матрицы также заносятся «1».
2. В связи с тем, что определяющим при включении каждого отдельного индивида в подгруппу является мнение всех членов этой подгруппы, а не самого этого индивида, при анализе матрицы описаний (социометрической матрицы) необходимо определять попарную связь (сходство) ее столбцов, а не строк. Действительно, можно считать, что i-й член группы входит в одну подгруппу с j-м членом в том случае, если их выбирают одинаковые члены группы. В этом случае при сравнении i-го и j-го столбца будет наблюдаться относительно большое число совпадающих выборов, сделанных одними и теми же членами группы. Отметим, что взаимные выборы i-го и j-го членов группы при этом тоже могут имплицитно учитываться наравне с другими совпадающими выборами. Это становится возможным благодаря подстановке единиц на главную диагональ матрицы сходства. Действительно, в том случае, если бы на главной диагонали отсутствовали единицы, при определении коэффициента сходства двух рядов, содержащих взаимные выборы, число совпадающих выборов уменьшилось бы при увеличении числа несовпадающих выборов. Соответственно уменьшился бы коэффициент, отражающий сходство этих рядов. Исключение единиц с главной диагонали матрицы сходства означало бы исключение учета взаимных выборов при определении состава подгрупп.
В качестве меры сходства описаний i-го и j-го членов группы служила величина
Sij = 2Nc / N0, (1)
где Nc — число совпадений выборов в i-м и j-м столбцах; N0 — суммарное число выборов в i-м и j-м столбцах.
114
Величина сходства может изменяться от 0, когда совпадающие выборы в i-м и j-м столбцах отсутствуют, до 1, когда в i-м и j-м столбцах все имеющиеся выборы совпадают. Совпадение или несовпадение «невыборов», т.е. нулей или пропусков, в матрице описаний не учитывается при определении сходства. Выбор Sij в качестве меры сходства вполне обоснован и при неодинаковом количестве выборов различных членов группы (что, конечно же, всегда имеет место в реальных условиях эксперимента). Действительно, если человек получает большое количество выборов, то вероятнее всего, что он принадлежит к подгруппе с большим количеством членов, если малое — то к подгруппе с малым количеством членов; т.е. лица, получившие существенно различное количество выборов, должны принадлежать к различным подгруппам (хотя, несомненно, возможны исключения). Сравнивая данные человека, получившего большое количество выборов, с данными человека, получившего малое количество выборов, вряд ли можно получить коэффициент сходства, величина которого превышает пороговое значение 0,5. При этом данные люди будут отнесены к различным подгруппам. Однако при не очень сильном различии количества выборов возможен вариант, когда коэффициент сходства может оказаться больше 0,5 и эти люди будут сгруппированы в одну подгруппу. В приведенном ниже конкретном примере 4-й член группы, получивший 10 выборов, включен в одну подгруппу с 15-м, получившим всего 6 выборов. С другой стороны, 10-й член группы, получивший 9 выборов, отнесен в другую подгруппу. Следовательно, при определении коэффициента сходства решающее значение имеет не количество выборов, а их качественный состав.
Рассчитанные при попарном сравнении столбцов матрицы описаний коэффициенты сходства сводились в матрицу коэффициентов сходства, симметричную относительно главной диагонали.
3. Построение матрицы коэффициентов сходства позволяет перейти к следующему этапу— непосредственно группировке, объединению в одну подгруппу (таксон, кластер) таких членов группы, описание которых наиболее сходно и которые вместе с тем наиболее сильно отличаются от других членов группы. Процедура группировки состояла в том, что каждый член группы рассматривался как «центр» образования возможной подгруппы и для него из соответствующих строк (или равных им столбцов) матрицы коэффициентов сходства определялись все те члены группы, коэффициенты сходства которых с «центральным» были больше 0,5.
Выбор порогового значения коэффициента сходства на уровне 0,5 обусловлен тем, что в случае, когда коэффициент сходства между «центральным» и другими членами подгруппы будет равен или меньше 0,5, данные члены группы могут с равной или большей вероятностью принадлежать другой подгруппе. Следовательно, их не нужно включать в подгруппу с данным «центральным» членом. Если увеличить пороговое значение коэффициента сходства выше 0,5, то в числе самостоятельных, не сгруппированных ни в одну подгруппу членов могут оказаться те, которые с большой вероятностью могут быть отнесены к вполне, определенной подгруппе. Эмпирическая проверка правильности выбора порогового значения коэффициента сходства показала, что при уменьшении этого значения до уровня меньше 0,5 возрастает численный состав подгрупп и усиливается «взаимопроникновение» подгрупп друг в друга, т.е. увеличивается число людей, которые могут входить одновременно в различные подгруппы; при увеличении этого значения до уровня больше 0,5 возрастает число членов группы, не включенных ни в одну подгруппу.
Таким образом, для каждого члена группы, выбранного в качестве «центра», была составлена своя возможная подгруппа. Каждая подгруппа отличалась от другой как по количеству членов, так и по величине сходства составляющих их членов с «центральным».
Для того чтобы определить качество (компактность) полученных подгрупп, была введена мера D, по смыслу близкая к понятию плотности, используемому в физике. Она вычислялась по формуле
![]() (2)
(2)
где N — число членов, включенных в данную подгруппу; Ŝij — средний коэффициент сходства между «центральным» членом и остальными членами подгруппы; (1 — Ŝij)—величина, противоположная по смыслу среднему сходству и характеризующая среднее «расстояние» между составляющими подгруппу членами и «центральным» членом подгруппы.
Величина плотности D может изменяться от 1, когда все коэффициенты сходства членов группы с данным «центральным» членом равны нулю, до ∞, когда все коэффициенты сходства членов подгруппы с «центральным» членом и, следовательно, друг с другом равны 1. В этом случае при Sij=1 возникает ситуация деления N на 0, что и дает ∞. На практике этот крайний случай возникает чрезвычайно редко. Однако при составлении программы на ЭВМ необходимо учитывать эту возможность деления числа на ноль. Поэтому при Sij=1 плотности D может быть присвоено достаточно высокое положительное конечное значение, например 99,99.
Для каждой выделенной подгруппы рассчитывается коэффициент плотности, а затем отбиралась такая подгруппа, плотность которой была максимальной. Поскольку в качестве «центров» образования подгрупп были рассмотрены все члены группы, невозможно обнаружить другую подгруппу, которая была бы более плотной, чем выбранная.
Те члены группы, которые образовали данную подгруппу, исключались из дальнейшего рассмотрения. Для этого вычеркивались соответствующие этим членам столбцы и строки матрицы коэффициентов сходства.
Затем процедура группировки повторялась вновь. Каждый из оставшихся членов группы рассматривался как возможный центр образования таксона, в который включались те из оставшихся членов группы, у которых коэффициент сходства с «центральным» был бы больше 0,5. Вновь для всех возможных сформированных подгрупп рассчитывалась величина
115
плотности и из этих подгрупп отбиралась та, плотность которой была максимальной. Члены группы, вошедшие в данную подгруппу, исключались из дальнейшего рассмотрения, т. е. из матрицы коэффициентов сходства вычеркивались соответствующие строки и столбцы. Процедура группировки повторялась вновь до тех пор, пока между оставшимися членами группы обнаруживались коэффициенты сходства, превышающие 0,5 и позволяющие группировать отдельных членов группы в подгруппы. Когда в матрице коэффициентов сходства не оставалось коэффициентов, превышающих 0,5, процедура группировки прекращалась. Оставшиеся члены группы рассматривались как самостоятельные, не включенные ни в какую подгруппу.
4. В связи с тем, что на каждом этапе классификации выделялись подгруппы максимальной плотности, вся классификация в целом может считаться оптимальной, не требующей специальной проверки ее качества. Отсутствует также необходимость в перегруппировке выделенных подгрупп с целью улучшения качества классификации.
*
Особо следует остановиться на вопросах точности классификации. Можно сказать, что любому алгоритму классификации присущи ограничения точности двух видов.
Неточности первого вида представляют собой отражение в процедуре классификации ограниченности концепции выделения подгрупп, положенной в основу создания алгоритма классификации.
Их нельзя считать собственно недостатками классификации. Принципиально невозможно представить такую классификацию, которая была бы полностью свободна от этих недостатков в связи с тем, что любая концепция выделения подгрупп учитывает не все, а только наиболее значимые факторы. В данной классификации неточности этого вида обусловлены тем, что в качестве главного условия выделения подгрупп рассматриваются мнения (выборы) членов подгруппы. Авторы считают, что именно это условие является главным в подавляющем большинстве случаев, однако допускают возможность другой концепции выделения подгрупп. Например, выделение подгруппы на основании анализа мнения отдельных членов подгруппы и производимых ими выборов, на основании анализа исключительно взаимных выборов и т.д. В этом случае процедуре классификации были бы присущи другие неточности, определяемые особенностями соответствующей концепции.
Неточности второго вида относятся собственно к процедуре классификации. Отметим, что точность классификации не может повышаться беспредельно и, как справедливо отмечают И.И. Елисеева и В.О. Рукавишников, точность и содержательная, практическая значимость анализа при достижении некоторого предела «становятся почти взаимоисключающими характеристиками» [2; 45]. Следовательно, точность классификации должна удовлетворять требованиям практики. Если подходить с этими требованиями к оценке точности предлагаемой классификации, то ее можно считать вполне удовлетворительной.
В то же время точность предлагаемой классификации может быть существенно повышена путем усложнения процедуры формирования возможных подгрупп. Так, например, можно использовать такую процедуру, когда каждый новый член, включается в подгруппу в том случае, если он имеет высокий коэффициент сходства не только с «центральным» членом, но и со всеми другими, уже включенными ранее в подгруппу. Авторы считают, что реализация такого алгоритма, существенно усложнив анализ, привела бы к получению избыточной точности, не требующейся в практических целях.
*
Для того чтобы проиллюстрировать действие данной процедуры классификации, рассмотрим конкретный пример выделения подгрупп в школьном классе. На момент обследования присутствовало 16 человек (по списку 21 ученик). Каждому учащемуся предлагалось выбрать людей из класса (включая и отсутствующих на момент обследования), с которыми они чаще всего общаются, поддерживают наиболее тесные отношения. Количество выборов практически не ограничивалось. Результаты выборов сведены в обычную социометрическую матрицу (матрицу описаний): по строкам — порядковый номер того учащегося, который выбирает; по столбцам — порядковый номер того учащегося, которого выбирают (см. табл. 1).
Попарное сравнение столбцов матрицы описаний позволяет построить матрицу коэффициентов сходства, рассчитанных по формуле [1]. Анализ матрицы коэффициентов сходства позволяет выделить все возможные подгруппы, определить их плотность по формуле [2] и выбрать наиболее плотную (см. табл. 2). Наиболее плотной оказалась подгруппа, включающая № 1, 4, 5, 8, 9, 11; 15 с центром № 9 и плотностью 31,44. Номера включенных в нее членов группы вычеркиваются из матрицы коэффициентов сходства, и группировка повторяется вновь.
Теперь наиболее плотной оказывается подгруппа, включающая № 2, 3, 6, 10, 12, 16 с центром № 2 и плотностью 23,92. Номера включенных в нее членов группы также вычеркиваются из матрицы коэффициентов сходства.
Оставшиеся в матрице коэффициенты сходства не превышают 0,5, и, следовательно, группировка должна быть прекращена.
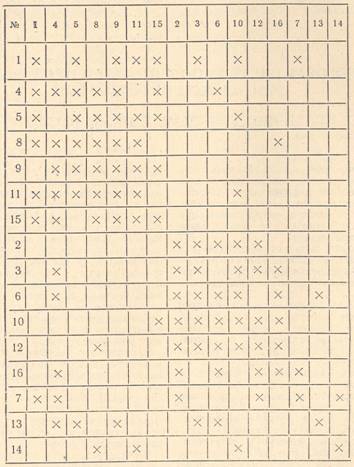
Все не включенные в подгруппы члены класса (№ 7, 13, 14) должны рассматриваться как самостоятельные. Перестроенная с учетом результатов классификации новая социометрическая матрица дает наглядное представление о возможностях данного алгоритма классификации (см. табл. 3).
Четко видны выделившиеся подгруппы и самостоятельные члены. (Можно сравнить с табл. 1, где дан начальный вид социометрической матрицы.) Обращает на себя внимание тот факт, что члены выделившихся подгрупп связаны друг с другом не только прямо, но и опосредованно, через других членов подгруппы. Необходимо отметить, что при определенных условиях в подгруппы могут быть включены те члены группы, которые отсутствовали
116
Таблица 1
МАТРИЦА ОПИСАНИЙ (НАЧАЛЬНЫЙ ВИД СОЦИОМЕТРИЧЕСКОЙ МАТРИЦЫ)
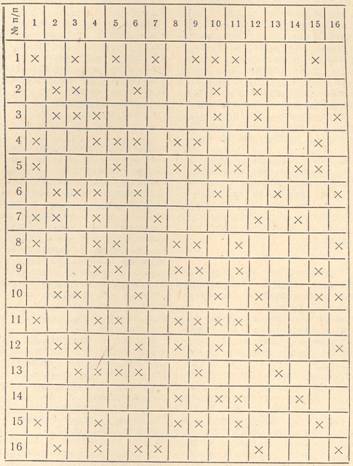
Таблица 2
ФРАГМЕНТ МАТРИЦЫ КОЭФФИЦИЕНТОВ СХОДСТВА (ДАННЫЕ С № 6 ПО № 15 ОПУЩЕНЫ), А ТАКЖЕ СОСТАВ И ПЛОТНОСТЬ ВСЕХ ВОЗМОЖНЫХ ПОДГРУПП
|
№ п/п |
1 |
2 |
3 |
4 |
5... 16 |
Состав подгрупп |
Плотность |
|
1 |
1,00 |
0,14 |
0,14 |
0,58 |
0,71...0,15 |
1, 4, 5, 8, 9, 11, 15 |
22,09 |
|
2 |
0,14 |
1,00 |
0,71 |
0,47 |
0,00...0,76 |
2, 3, 6, 10, 12, 16 |
23,92 |
|
3 |
0,14 |
0,71 |
1,00 |
0,35 |
0,28...0,61 |
2, 3, 6, 10, 12, 16 |
18,86 |
|
4 |
0,58 |
0,47 |
0,35 |
1,00 |
0.58...0,50 |
1, 4, 5, 8, 9 |
12,48 |
|
5 |
0,71 |
0,00 |
0,28 |
0,58 |
1,00...0,15 |
1, 4, 8, 9, 11, 15 |
23,75 |
|
6 |
0,14 |
0,71 |
0,71 |
0,47 |
0,28...0,61 |
2, 3, 6, 12, 16 |
14,91 |
|
7 |
0,39 |
0,39 |
0,19 |
0,30 |
0,19...0,22 |
7 |
1,00 |
|
8 |
0,66 |
0,13 |
0,13 |
0,55 |
0,66...0,28 |
1, 4, 5, 8, 9, 11, 15 |
21,10 |
|
9 |
0,79 |
0,00 |
0,26 |
0,66 |
0,93...0,14 |
1, 4, 5, 8, 9, 11, 15 |
31,44 |
|
10 |
0,37 |
0,62 |
0,75 |
0,31 |
0,37...0,53 |
2, 3, 10, 12, 16 |
12,83 |
|
11 |
0,71 |
0,00 |
0,14 |
0,47 |
0,71...0,15 |
1, 5, 7, 9, 11, 15 |
22,12 |
|
12 |
0,15 |
0,92 |
0,61 |
0,37 |
0,00...0,66 |
2, 3, 6, 10, 12, 16 |
21,10 |
|
13 |
0,00 |
0,22 |
0,44 |
0,33 |
0,22...0,25 |
13 |
1,00 |
|
14 |
0,39 |
0,19 |
0,00 |
0,15 |
0,19...0,00 |
14 |
1,00 |
|
15 |
0,61 |
0,15 |
0,30 |
0,37 |
0,61...0,16 |
1, 5, 8, 9, 11, 15 |
16,05 |
|
16 |
0,15 |
0,75 |
0,61 |
0,50 |
0.15...1,00 |
2, 3, 6, 10, 12, 16 |
16,66 |
117
Таблица 3
СОЦИОМЕТРИЧЕСКАЯ МАТРИЦА, ПЕРЕСТРОЕННАЯ С УЧЕТОМ РЕЗУЛЬТАТОВ КЛАССИФИКАЦИИ
при проведении выборов, но которые выбирались членами класса.
Преимущество данной системы классификации перед другими существующими системами состоит в том, что она является полностью формализованным методом выделения подгрупп в группах и соответствует требованиям, предъявляемым к системам классификации «без учителя», т.е. не требует априорного ограничения ни числа подгрупп, ни количества составляющих их членов.
Классификация оптимальна, поскольку позволяет выявить самый лучший вариант разбиения группы на подгруппы и определить наиболее плотные подгруппы. Точность классификации вполне удовлетворяет требованиям практики. Предлагаемый алгоритм классификации легко может быть реализован в виде программы для обработки данных на ЭВМ. Наибольший труд при этом приходится на составление матрицы коэффициентов сходства. Однако при наличии определенных навыков и использовании рациональных приемов работы (например, прозрачной пленки при попарном сравнении столбцов матрицы описаний) время ручной обработки не так уж велико: ручная обработка результатов группы, состоящей из 15—17 человек, занимает около 2 часов.
Данная методика классификации апробирована при проведении психологического обследования 58 школьных классов и позволила получить существенно новые данные о динамике межличностных отношений в старших классах. Естественно, что эта методика может применяться для анализа структуры межличностных отношений в любых малых группах, когда у исследователя возникает необходимость рассмотрения подгрупп как структурных единиц группы.
1. Горбатенко А. С., Жак С. В. Метод вторичной таксономии для оценки анкетных тестов. — В кн.: Системный анализ и моделирование социально-экономических процессов. Труды II Всесоюзного семинара. М.: ВНИИ системных исследований, 1981. С. 130—136.
2. Елисеева И. И., Рукавишников В. О. Группировка, корреляция, распознавание образов. — М., 1977. — 144 с.
118
3. Коломинский Я. Л. Дифференциация социальной психологии и проблемы воспитания. — Вопросы психологии. 1983. № 2. С. 60—67.
4. Методы социальной психологии / Под ред. Е.С. Кузьмина, В.В. Семенова. — Л., 1977. — 176 с.
5. Паниотто В. И. Структура межличностных отношений. — Киев, 1975. — 128 с.
Поступила в редакцию 6.VII 1983 г.