116
ПРИМЕНЕНИЕ НОРМИРОВАННЫХ КОЭФФИЦИЕНТОВ В ИССЛЕДОВАНИИ ВЕРОЯТНОСТНОГО ПРОГНОЗИРОВАНИЯ
В. И. СТЕПАНСКИИ, А. К. ОСНИЦКИИ, В. Б. ГРЕНАДЕР
НИИ общей и педагогической психологии АПН СССР, Москва
Прогнозирование событий представляет собой один из важнейших функциональных компонентов любого поведенческого акта. Исследование механизмов прогнозирования всегда будет поэтому актуальным для экспериментальной психологии. В рафинированном виде прогноз изучают в модельной лабораторной деятельности, известной под названием игра в угадывание. Условия ее заключаются в том, что испытуемому предлагают шаг за шагом разгадывать последовательность двух или нескольких символов (или событий), причем после каждого очередного предсказания сообщается результат.
Последовательность предсказаний можно рассматривать как ряд символов, сконструированный испытуемым в процессе работы с последовательностью экспериментатора. Такой ряд репрезентирует прогностическую деятельность испытуемого, и вместе с тем содержит в себе попытки сбора информации о последовательности [3], [4], [7]. В связи с тем что в последовательности экспериментатора каждый символ появляется с определенной частотой, в ряду испытуемого1 обычно подсчитываются частоты встречаемости символов, причем эти частоты принимаются за вероятности предсказания событий, а сам прогноз в соответствии с этим нередко называют вероятностным. Кроме вероятностных характеристик, для ряда вычисляются еще и показатели структурности: протяженность и количество блоков повторяющихся символов [2], [3], [4], условные вероятности переходов от символа к символу и от одной альтернативы к другой [1], [6], показатели связи предшествующего и последующего предсказаний и показатели точности отображения последовательности подкреплений [1].
Выявленные показатели ряда предсказаний испытуемого сопоставляют с соответствующими показателями последовательности экспериментатора и делают выводы о степени адекватности отражения испытуемым частотных характеристик последовательности, о зависимости предсказаний от успешности предшествующих проб, о характере стратегии испытуемого.
Возможность применения количественных расчетов — бесспорно существенное достоинство вероятностно-статистического метода анализа результатов прогностической деятельности. Однако ни один из указанных выше показателей не связан непосредственно с общей успешностью предсказаний испытуемого, т. е. с соотношением общего количества верных и неверных предсказаний. Так, например, в случае периодичной последовательности символов 010101010101 названный испытуемым ряд 101010101010, несмотря на полное соответствие вероятностно-статистических характеристик, не обеспечит испытуемому ни одного верного предсказания. Аналогичная картина может наблюдаться и для апериодичных последовательностей, поэтому помимо вероятностно-статистических показателей имеет смысл определять и специальный показатель совмещенности ряда испытуемого с последовательностью экспериментатора.
Основная трудность, возникающая перед исследователем на этом пути, состоит в. том, что требуется отыскать метод разделения ошибок испытуемого на две категории: ошибки, связанные с неполным отображением структуры последовательности в структуре ряда, и ошибки, вызванные неточным совмещением структур, тождественных по своим характеристикам.
В настоящей статье описывается алгоритмическая процедура решения подобной задачи, реализованная с помощью ЭВМ МИР-1.
В проведенном экспериментальном исследовании применялась последовательность,
117
составленная из альтернативных символов «+» (плюс) и «—» (минус), содержащихся в равных количествах — по 80 каждого. Плюсы группировались в блоки либо по два, либо по три подряд (++ или +++), а минусы — в блоки либо по два, либо по четыре подряд ( –– или
–––––), а их общая последовательность имела следующий вид1:
![]()
(знаком «+» или «—» обозначается альтернатива, цифрой — длина блока этой альтернативы).
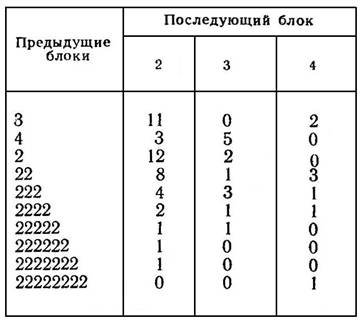
Важной характеристикой такой последовательности является матрица линейных переходов от блока к блоку, которая описывает число переходов к блоку данной длины после одного, двух, трех и т. д. блоков такой же или альтернативной длины. Такие матрицы можно строить, для каждой альтернативы по отдельности (табл. 1) и для всей последовательности в целом (табл. 2), Ранее полученные экспериментальные данные показали, что субъективный учет переходов такого рода и вырабатываемый на его основе прогноз играют существенную роль в формировании подготовки испытуемого к исполнению последовательных сенсомоторных реакций [5].
Таблица 1
МАТРИЦА ЛИНЕЙНЫХ ПЕРЕХОДОВ ДЛЯ ОТДЕЛЬНЫХ АЛЬТЕРНАТИВ
«ПЛЮС» И «МИНУС»
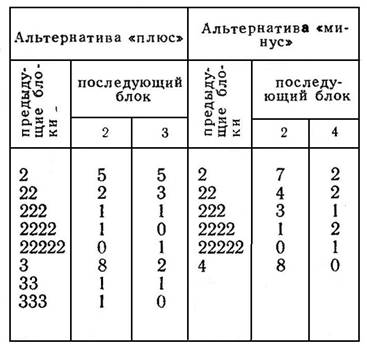
Таблица 2
МАТРИЦА ЛИНЕЙНЫХ ПЕРЕХОДОВ ДЛЯ ЦЕЛОСТНОЙ
ПОСЛЕДОВАТЕЛЬНОСТИ
Аналогичные матрицы можно строить и для переходов от символа к символу, однако в данном исследовании это не представляет интереса, так как перед началом эксперимента испытуемым в инструкции сообщали о блочной организации символов каждой альтернативы и обязательно проверяли правильность усвоения инструкции. Это позволило сократить период научения при работе с данным алфавитом и обеспечить тождественность алфавита блоков в последовательности экспериментатора и в ряде испытуемого, что повышает точность количественных оценок, получаемых при сопоставлении последовательности и ряда.
Все прочие условия были обычными; регистрация предсказаний испытуемого и сообщение ему результатов производились автоматическим устройством, темп работы был свободным, делать записи испытуемым не разрешалось.
В основу предлагаемого метода анализа материалов положены два допущения: 1) хотя, испытуемый называет одиночные символы, но прогнозирует при этом целостные блоки; 2) испытуемый немедленно анализирует каждое ошибочное предсказание, подставляя «в память» верный символ на место неверно предсказанного. Исходя из этих допущений, мы и предприняли попытку выявить тот ряд, который используется испытуемым в качестве опорного при формировании очередных прогнозов.
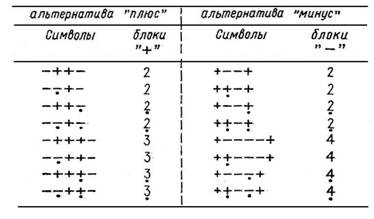
Процедура обработки индивидуальных результатов состояла в следующем. Ряд названных испытуемым символов преобразовывали в ряд блоков, пользуясь таблицей перевода в блочный алфавит (табл. 3).
118
Таблица 3
ТАБЛИЦА ПЕРЕВОДА СИМВОЛОВ РЯДА ИСПЫТУЕМОГО В БЛОКИ
(ТОЧКОЙ ОТМЕЧАЮТСЯ НЕВЕРНЫЕ ПРЕДСКАЗАНИЯ)
Затем для полученного блочного ряда, в. котором присутствуют как верно, так и неверно предсказанные блоки, проводится процедура условного исправления ошибок — перевод ошибочных блоков в истинные, после чего записывается матрица линейных переходов для ряда испытуемого.
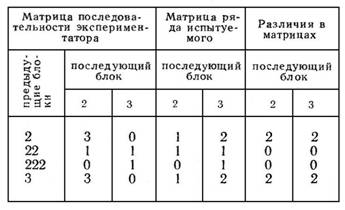
Рассмотрим построение матрицы на конкретном образце укороченной последовательности, которая имеет, например следующий вид:

Составляем матрицу переходов (табл. 4), передвигаясь лишь по длине ступенек блочного ряда с исправлением, и построчно сопоставляем ее с матрицей переходов «плюсов» в последовательности экспериментатора (см. табл. 4). Результаты сопоставления представлены в правой части табл. 4; где на пересечениях строк и столбцов проставлены построчные расхождения матрицы ряда и матрицы последовательности; Далее путем суммирования всех расхождений матрицы ряда и матрицы последовательности и деления полученной суммы пополам (удвоение расхождений: происходит в: связи с тем, что ошибка в количестве переходов для блока одной: длины автоматически влечет за собой ошибку и для блока альтернативной длины) отыскиваем количество ошибок в отражении структуры по символам «+», которое составляет в данном примере 4 ошибки. Найденные ошибки структуры вычитаем из общего
Таблица 4
МАТРИЦЫ РЯДА ИСПЫТУЕМОГО И ПОСЛЕДОВАТЕЛЬНОСТИ ЭКСПЕРИМЕНТАТОРА
119
количества ошибок, допущенных испытуемым при предсказывании данного символа, и таким образом определяем количество ошибочных предсказаний, связанных с неточным совмещением структур ряда и последовательности (2 ошибки).
Абсолютные величины ошибок отражения структуры и ошибок совмещения нормируются и преобразуются в относительные коэффициенты отражения структуры (Ко) и совмещения структур (Кс). Соответствующие формулы имеют вид:

где N — общее число блоков; hо — число ошибок структуры; hс — число ошибок совмещения (в данном примере Ко+ = 0,50; Кс + = 0,66). Нетрудно видеть, что область значений каждого коэффициента находится в пределах от 0 до 1, причем 0 соответствует полному неотражению (или несовмещению) структуры, а 1 — полному отражению (или совмещению).
Произведение этих коэффициентов (Кос = Ко × Кс) представляет собой коэффициент ряда и последовательности. Значения Кос лишь незначительно отличаются от реальной успешности испытуемого, которая вычисляется как отношение количества верных предсказаний к общему количеству блоков (табл. 5), что говорит о репрезентативности данного коэффициента как оценки эффективности прогнозирования.
Таблица 5
ИТОГОВЫЕ ЗНАЧЕНИЯ ОБОЩЕННЫХ И РАЗДЕЛЬНЫХ
КОЭФФИЦИЕНТОВ (в %)
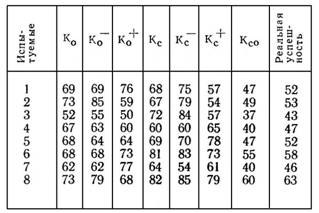
Три других произведения позволяют оценить в отдельности долю ошибок, совершенных: а) из-за неполного совмещения структур — [Ко × (1— Кс)], б) из-за неполного отражения структуры — [Кс × (1—Ко)], в) из-за потери связи с последовательностью [(1 — Ко) × (1— Кс)]. Кроме того, путем сложения произведений (б) и (в) можно получить количественную оценку доли случайных предсказаний, которая в итоге равняется 1 — Ко.
Как показало проведенное нами исследование, коэффициенты Kо+ и Ко-, а также Кс+ и Кс-, подсчитанные для одного и того же испытуемого, могут у некоторых испытуемых значительно различаться между собой, что указывает на неодинаковое отношение этих испытуемых к предсказываемым альтернативам (см. табл. 5).
Чтобы судить о достоверности различий коэффициентов, необходимо по каждому из них иметь данные о значении эмпирической дисперсии, которые можно получить из статистического анализа совокупности значений Ко и Кс вычисляемых пошагово, начиная с 10-го блока и заканчивая 65-м блоком. Анализ последовательной динамики этих коэффициентов показал, что у каждого испытуемого в начале работы на участке протяженностью в 15—30 блоков Ко и Кс неуклонно возрастают, что, по-видимому, отражает процесс научения. Показателем качества научения может служить величина коэффициента к концу этого периода, а показателем протяженности периода научения может служить количество блоков, составляющих этот период. В тех случаях, когда участок научения аппроксимируется линейной функцией, можно получить и показатель темпа научения — частное от деления величины коэффициента на число блоков в периоде научения.
Кроме начального роста у ряда испытуемых к концу работы (с 55—60-го блока) наблюдается некоторое снижение значений коэффициентов. Это явление может быть связано либо с психическим пресыщением данной деятельностью, либо с переходом на какой-то иной уровень работы с последовательностью. Возможность утомления испытуемых или распада навыка в данных условиях маловероятна, поскольку продолжительность опыта была незначительной.
В связи с наличием в предсказательной деятельности испытуемых начального периода научения и конечного периода спада итоговые значения Ко и Кс, рассчитанные для всего ряда в целом, не могут характеризовать средние достижения испытуемых, так как они отражают суммативный уровень, достигнутый к моменту окончания опыта. В связи с этим в качестве характеристики среднего достижения по каждому коэффициенту нужно вычислять среднее для динамики значений, полученных на стационарном (бестрендовом) отрезке ряда предсказаний испытуемого.
Итак, описанная процедура обработки материалов эксперимента по вероятностному прогнозированию позволяет получить индивидуальные количественные показатели, которые характеризуют: 1) успешность отражения структурных особенностей внешней
120
среды (Ко), 2) успешность совмещения конструируемой субъектом структуры с объективно, существующей (Кс). Каждый показатель представляет собой нормированный коэффициент, принимающий значения на отрезке от 0 до 1. Пошаговый расчет коэффициентов дает возможность вычислять эмпирическую дисперсию, а также выявлять и количественно описывать динамику начального научения и любые изменения эффективности прогнозирования по ходу деятельности.
На практике вычисление Ко и Кс как индивидуальных характеристик может производиться в целях составления профессиограмм для тех видов деятельности, в которых прогнозирование занимает центральное место.
1. Бубашевский Б. Г., Меницкий Д. Н. Особенности отображения вероятностной структуры внешней среды при некоторых патологических состояниях высшей нервной деятельности. — В сб.: Шизофрения и вероятностное прогнозирование. — Труды ЦОЛИУ(в), т. 174. — М., 1973, с. 49—58.
2. Иванников В. А., Цискаридзе М. А. «Микростратегия» испытуемых и среднее время реакции. — В сб.: Вопросы экспериментального исследования скорости реагирования. Тарту, 1971, с. 46—47.
3. Осницкий А. К. Вероятностное прогнозирование и эффективность опознания: Автореф. канд. дис. — М., 1972. —.24 с.
4. Переслени Л. И. Частота сигналов в вероятностной среде и стратегия поведения оператора. — Вопросы психологии, 1978, № 6, с. 120—124.
5. Степанский В. И., Осницкий А. К. Зависимость времени реакции от структуры прогноза в вероятностно-детерминированной среде. — В сб.: Вероятностное прогнозирование в деятельности человека. — М., 1977, с. 273—279.
6. Цискаридзе М. А., Иванников В. А. Субъективная вероятность и время реакции. — Вопросы психологии, 1973, № 2, с. 127—131..
7. Ямпольский Л. Т. Сравнительный анализ адаптивного поведения здоровых и больных шизофренией. Автореф. канд. дис. — М., 1974. — 23 с.